在使用数据库/数据仓库的过程中,我们可能会遇到以下几个情况:
- 需要得到的数据既要包括聚合后的数据, 也需要包括没被聚合的字段
- 需要获取多个字段前n条的数据
这个时候如果我们使用传统的group by聚合函数的话,可能会出现以下的问题,
对于第一种情况,如果sql语句使用group by的话,select只能包括group by的字段以及根据它们聚合得到的字段,如果select包括其它没有参与聚合的字段的话,sql会报错,此时如果不把它们也放入group by语句里的话,可能语句就无法执行
对于第二种情况,如果用group by的话语句就会比较复杂
为了解决这些实际操作中可能会遇到的问题,我们可以使用窗口函数来进行group by的替代。窗口函数可以让聚合列和基础列同时显示在查询结果中。
窗口函数可以分为两大类,聚合窗口函数和排序窗口函数。它们均有以下类似的调用格式:
{windows_func}() over(partition by xx order by xx)
很多数据库均支持窗口函数,MySQL从8.0版本开始也支持窗口函数。
1. 聚合窗口函数
顾名思义,这一类窗口函数是实现类似于group by的聚合的功能。它和group by的区别是, group by的话对于聚合的字段的话只会显示一行结果,而聚合窗口函数的话可以在符合条件的每一行中均显示相关的结果。
聚合窗口函数包括以下几个类别:
- sum()
- count()
- max()
- min()
- avg()
举个栗子,假设以下这张score表是某小学的学生成绩单。
| user_id | user_name | class_name | chinese_score | math_score | english_score |
|---|---|---|---|---|---|
| 1 | 张三 | 一班 | 60 | 80 | 80 |
| 2 | 李四 | 二班 | 70 | 90 | 60 |
| 3 | 王五 | 一班 | 60 | 70 | 70 |
| 4 | 赵六 | 一班 | 70 | 99 | 99 |
| 5 | 小明 | 一班 | 75 | 75 | 50 |
| 6 | 小红 | 二班 | 89 | 89 | 89 |
| 7 | 小李 | 二班 | 70 | 89 | 90 |
| 8 | 小五 | 二班 | 80 | 70 | 60 |
| 9 | 小六 | 二班 | 50 | 80 | 65 |
| 10 | 小七 | 三班 | 45 | 65 | 76 |
| 11 | 中二 | 三班 | 60 | 80 | 60 |
| 12 | 中三 | 三班 | 61 | 79 | 60 |
这时如果我们想知道每个班数学成绩良好(>=75分)的人数以及班级每个同学的数学成绩和同班级最高分、最低分、平均分的差距的话,就可以使用窗口函数来进行查询。
1 | select *, avg(math_score) over (partition by class_name) as avg_math_score, |
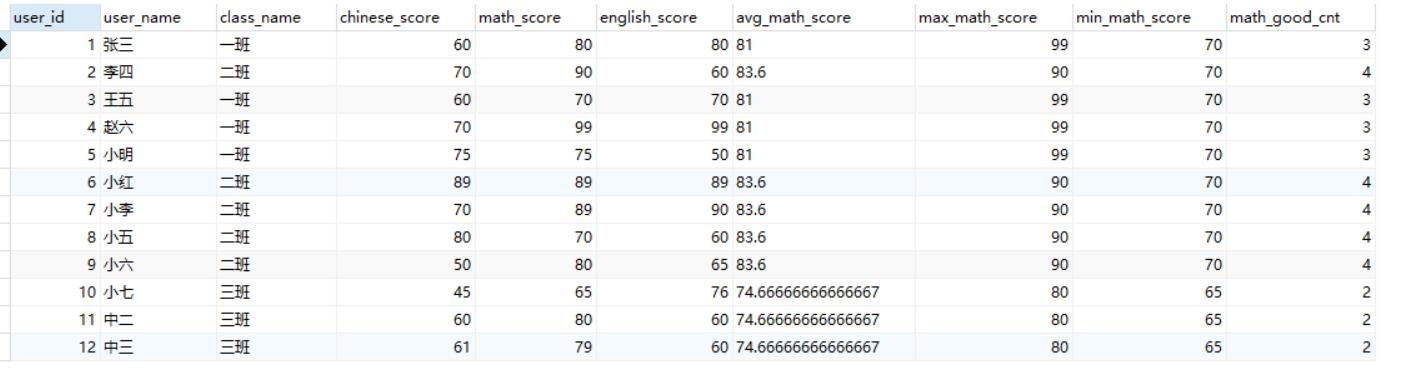 可以看到结果如上。聚合开窗函数的partition by类似于数据库的group by聚合操作,在这个SQL例子中,开窗函数根据不同班级将数据分组,然后求出对应的平均值,最大值以及最小值。这里的 count() 开窗函数使用了case when语句筛选了数学成绩大等于75分的同学,然后进行聚合计算。
可以看到结果如上。聚合开窗函数的partition by类似于数据库的group by聚合操作,在这个SQL例子中,开窗函数根据不同班级将数据分组,然后求出对应的平均值,最大值以及最小值。这里的 count() 开窗函数使用了case when语句筛选了数学成绩大等于75分的同学,然后进行聚合计算。
2. 排序窗口函数
排序窗口函数是另外一种窗口函数,它主要获取每一行的数据按照某些字段聚合之后,关于某一字段的排名。主要有以下几种:
- row_number() over(order by)
- rank() over(order by)
- dense_rank() over(order by)
- ntile(分组数) () over(order by)
排序窗口的函数排序默认是升序排序,如果需要降序排序的话需要在后面加上DESC。同时排序窗口支持Partition分组,但是partition需要放在order by前面。(这个和group by类似)
关于row_number(), rank()和dense_rank(),它们的区别主要在于遇到有数据并列情况的时候的区别:
- row_number()排序的时候每一行都有唯一的排序编号,即使有并列的数据它们的rank也是不同的
(可以理解为row_number的排序一定要决出一个名次)- rank()和dense_rank()会给并列的数据相同的排序编号,区别是在给相同数据排序之后,rank()会留下若干个排名空位(取决于有几个相同数据),而dense_rank()不会。
(举个栗子,一个比赛要决出前三名,但是有两个并列第二的选手。这种情况下rank()排序的话就没有第三名,站在领奖台的依旧只有三位选手(第三名是空的)。但是用dense_rank()排序的话就会有四位选手站在领奖台)
至于ntile()的话它是根据分组数来进行均分分组的,比如分组数为2的话,那么就是排序之后前一半数据归为第1组,后一半数据归为第2组。如果数据没法均分,那么ntile会优先考虑多分数据到rank较小的分组中(比如要把{1, 3, 5, 8, 10)分为2组,那么{1, 3, 5}会分为第1组, {8, 10}会分为第2组)
继续举之前成绩单的例子,假设我们想知道每个班学生在班内的排名情况,那么我们可以用排序窗口函数来进行查看,
1 | select *, rank() over(partition by class_name order by math_score desc) as rank_rank, |
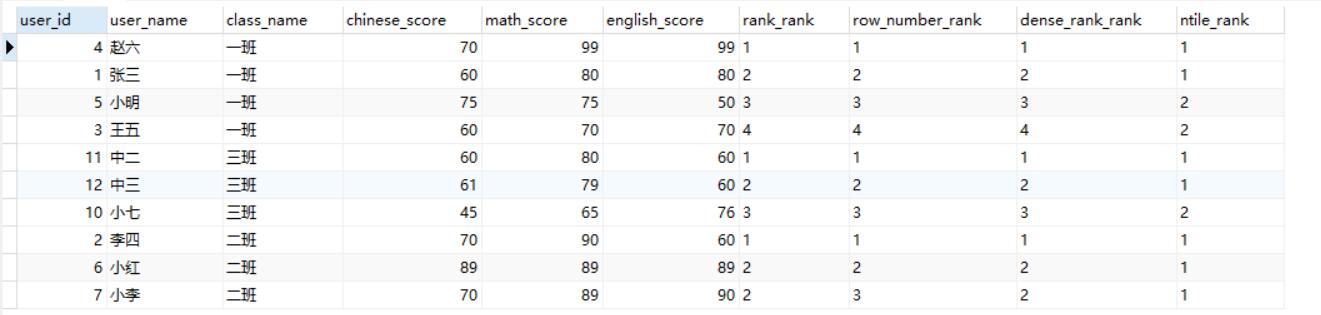 结果如图,从查询情况来看也可以发现不同排序窗口函数的区别。
结果如图,从查询情况来看也可以发现不同排序窗口函数的区别。
3. Value 窗口函数
英文名为Value Window Functions,没找到一个合适的中文翻译,因此就以value窗口函数来命名了。
这一类的窗口函数主要有以下四种
- Lag()
- Lead()
- First_Value()
- Last_Value()
3.1 Lag()和Lead()
Lag()函数的作用是返回当前行的前n行的某一列的值,Lead()函数是返回当前行后n行的某一列的值。
具体的参数如下:
LAG | LEAD (col, line_num, DEFAULT)
OVER (PARTITION BY ORDER BY)
col: 指定获取哪一列的字段
line_num:决定返回前/后多少行的值
default: 默认为None,如果找不到对应的值则返回该值。(比如要返回第一行的前两行数据,这种情况就是默认返回None)
order by 根据哪些字段排序,这决定了返回的前n行/后n行是按照哪个字段的排列为标准的。
举个栗子,假设有一张记录每个学生多次考试成绩的表。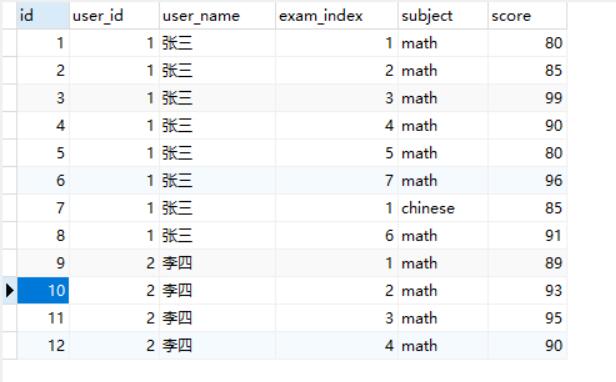
如果我们想要在一行里面知道该学生上一次的考试成绩和下一次的考试成绩的话,可以写如下的sql语句:
1 | select *, lag(score, 1) over (partition by user_id, subject order by exam_index) as last_score, |
可以看出在同一行中,显示出了学生当次,上一次和下一次的考试成绩。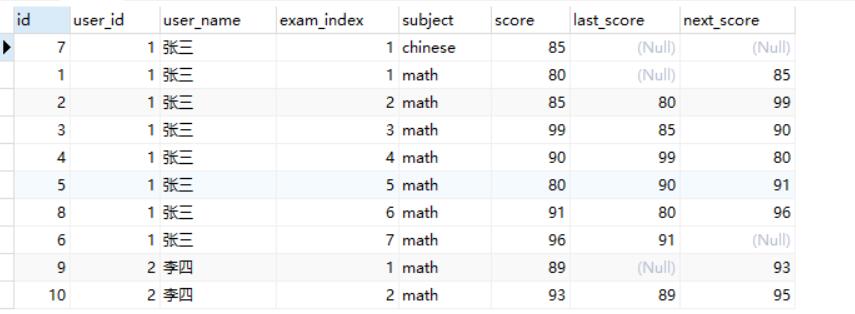
3.2 First_value()和Last_value()
这两个函数的作用是返回特定分组内的某一字段第一次出现的值和最后一次出现的值。
具体的参数如下:
FIRST_VALUE | LAST_VALUE (col (ignore nulls))
OVER (PARTITION BY ORDER BY)
比如我们想要在一行里面知道每个学生当次考试成绩,第一次考试成绩和最后一次考试成绩的话,可以写如下的sql语句:
1 | select *, first_value(score) over (partition by user_id, subject order by exam_index) as first_score, |
可以得到结果如下:
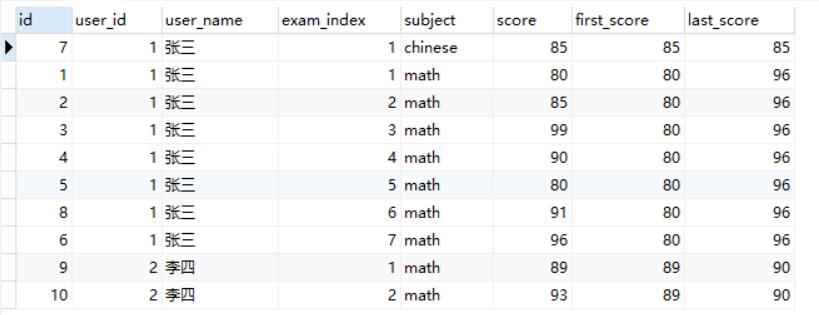 需要注意的是,这里last value的over参数后面加了个rows between unbounded preceding and unbounded following语句,这是为什么呢?因为last_value的默认选项是 BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,即默认是当前行和之前行比较,如果没加这个参数的话,每一行对应的last_value都是自己的值,而不是整体的最后的值。
需要注意的是,这里last value的over参数后面加了个rows between unbounded preceding and unbounded following语句,这是为什么呢?因为last_value的默认选项是 BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,即默认是当前行和之前行比较,如果没加这个参数的话,每一行对应的last_value都是自己的值,而不是整体的最后的值。
关于参数的ignore nulls选项,它是可选的,如果添加ignore nulls的话,那么如果说对应分组有NULL值的话,会单独列出来,而不会参与分组之内的first value计算。
以上便是关于SQL开窗函数的所有内容了。写完之后发现自己对于这方面的知识又巩固了:)。